In this blog you’ll learn how you can use PowerShell in combination with ARM Templates to propagate basically everything from your ARM Template into your DevOps CI/CD Pipeline (formerly known as VSTS – Visual Studio Team Services) so you can reuse the values in other ARM Templates, PowerShell or any other pipeline step which accepts parameters.
Part 1: The scenario background
The scenario we’ll work on in this blogpost, is this: We have a CI/CD Pipeline in Azure DevOps with a build pipeline (which validates the ARM templates and creates the drop package from the Git repo) and a release pipeline.
The solution contains two ARM templates which need to run separately from each other, but there are dependencies between the two templates. The second ARM template depends on specific output values from the first template (resource names and access keys for example).

The solution which will be deployed via the ARM Templates and scripts consists of an IoT Hub which sends its messages to Azure Stream Analytics, which then will store it on a blob storage container. All three Azure resources will be created and configured by the ARM templates. After the deployment completes, the Stream Analytics Job will be automatically started by the release pipeline.
Note: I’m aware that this scenario could easily be resolved in one ARM template or could have been solved with other approaches (e.g. variable libraries) instead of the solution explained in this blogpost. However, there might be scenarios in your CI/CD pipeline where you are dependent on output values from an ARM template to be used into another ARM template, PowerShell script or other type of task in the release pipeline.
Part 2: The Visual Studio solution
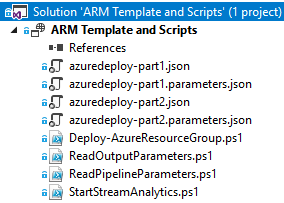
The solution consists of two ARM Templates (“Part 1” and “Part 2”) and three PowerShell scripts:
- ReadOutputParameters.ps1: this is the most important script for reading the ARM output into DevOps variables
- ReadPipelineParameters.ps1: this is a script for informational purposes and outputs all the DevOps variables into the pipeline logs so you can see what kind of variables are present
- StartStreamAnalytics.ps1: this PowerShell script is used to start the deployed Azure Stream Analytics instance and requires some parameters which we’ll need to retrieve from the “Part 2” ARM template
Part 3: Configure the ARM Templates
In the “outputs” section of the ARM Template, you can output basically everything related to the resources in your ARM Template. This can vary from fixed strings, objects, connection strings, configuration settings, arrays and more.
For this post, the focus will be on strings and secure strings.
As per the below example, the output section for the “Part 1” template will contain 4 strings:
- Output_IoTHubConnectionString (string): this is one of the main reasons why I’ve investigated this approach because the IoT Hub Connection string (including the endpoint) cannot be received outside the ARM Template where the IoT Hub is being provisioned
- Output_IoTHubName (string): this just outputs the input parameter for the name of the IoT Hub
- Output_IoTHubPrimaryKey (string): this outputs the primary key to access the IoT Hub under the “service” shared access policy
- Output_SIoTHubPrimaryKey (securestring): this outputs the same as #3, but then as securestring to ensure the key won’t be logged in any PowerShell and CI/CD Pipeline logs. This is always the recommended way to work with sensitive information, but for educational purposes of this blog, I’ve included #1 and #3 as normal strings in the solution
"outputs": {
"Output_IoTHubConnectionString": {
"type": "string",
"value": "[concat('Endpoint=',reference(resourceId('Microsoft.Devices/IoTHubs',parameters('iothub_name'))).eventHubEndpoints.events.endpoint,';SharedAccessKeyName=service;SharedAccessKey=',listKeys(resourceId('Microsoft.Devices/IotHubs/Iothubkeys', parameters('iothub_name'), 'service'), '2016-02-03').primaryKey,';EntityPath=',parameters('iothub_name'))]"
},
"Output_IoTHubName": {
"type": "string",
"value": "[parameters('iothub_name')]"
},
"Output_IoTHubPrimaryKey": {
"type": "string",
"value": "[listKeys(resourceId('Microsoft.Devices/IotHubs/Iothubkeys', parameters('iothub_name'), 'service'), '2016-02-03').primaryKey]"
},
"Output_SIoTHubPrimaryKey": {
"type": "securestring",
"value": "[listKeys(resourceId('Microsoft.Devices/IotHubs/Iothubkeys', parameters('iothub_name'), 'service'), '2016-02-03').primaryKey]"
}
}
Similarly, in the “Part 2” ARM Template, there are two output strings (which are required later to start the Stream Analytics job):
- Output_StreamAnalyticsName (string): this outputs the name of the Stream Analytics job
- Output_ResourceGroupname (string): outputs the name of the resource group, based on the dynamic “[resourceGroup().name]” function
Part 4: Configure the ARM Templates in the Azure DevOps release pipeline
When the ARM Templates are configured to output the values you need in other release pipeline steps, we need to configure the DevOps pipeline.
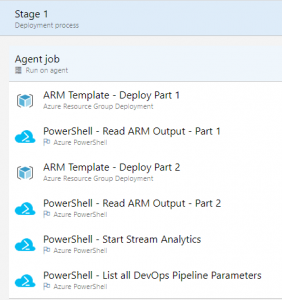
The release pipeline for this post consists of the below steps:
To properly configure the “Azure Resource Group Deployment” steps for part 1&2, we need to configure the “Deployment outputs” under the “Advanced” section:
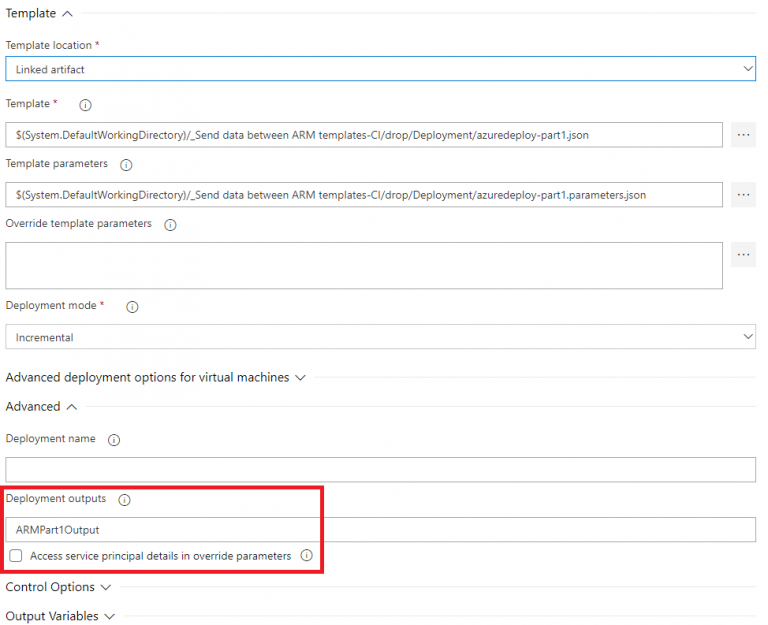
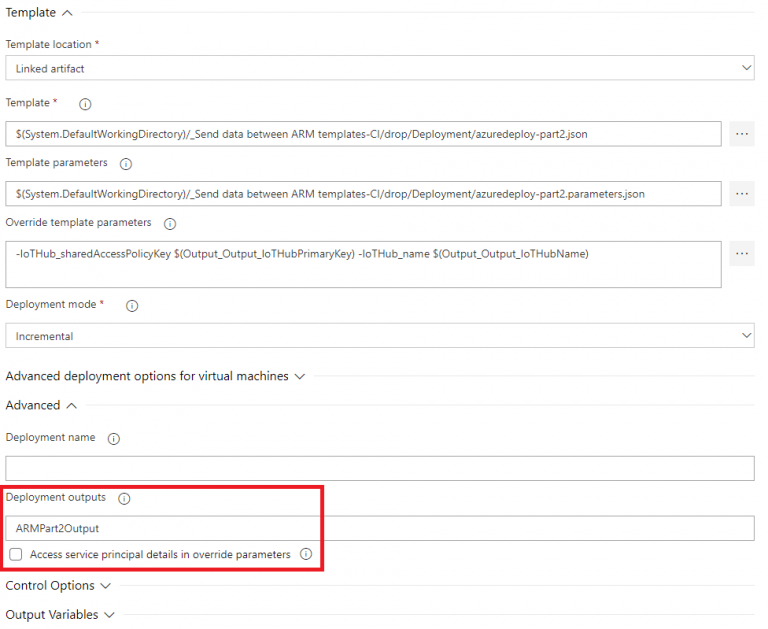
The name you will define here, will be the name of the pipeline variable which will contain all outputs from the ARM Template. In this case, for the first ARM template I’ll use “ARMPart1Output” and for the second ARM Template, I’ll use “ARMPart2Output” to ensure they won’t conflict with each other:
Part 5: Configure the Read ARM Output PowerShell script in the Azure DevOps release pipeline
Now the ARM Template output is available in the Azure DevOps pipeline, there is one more step we need to do to get the individual output values because currently it’s just a JSON string containing all the output.
This is where the “ReadOutputParameters.ps1” script and step helps. This script requires a parameter called “armOutputString” to convert the JSON into individual pipeline variables:
param (
[Parameter(Mandatory=$true)]
[string]
$armOutputString = ''
)
Write-Output "Retrieved input: $armOutputString"
$armOutputObj = $armOutputString | convertfrom-json
$armOutputObj.PSObject.Properties | ForEach-Object {
$type = ($_.value.type).ToLower()
$keyname = "Output_"+$_.name
$value = $_.value.value
if ($type -eq "securestring") {
Write-Output "##vso[task.setvariable variable=$keyname;issecret=true]$value"
Write-Output "Added VSTS variable '$keyname' ('$type')"
} elseif ($type -eq "string") {
Write-Output "##vso[task.setvariable variable=$keyname]$value"
Write-Output "Added VSTS variable '$keyname' ('$type') with value '$value'"
} else {
Throw "Type '$type' is not supported for '$keyname'"
}
}
Reading through the above PowerShell script, you can see that it converts the string from JSON into an object. Then next it loops through the object to read all individual values and write it into the pipeline using the “task.setvariable” command. If a securestring is found, the “issecret” flag will be set to “true” to ensure the value remains a secret in the pipeline. As of now the script is written to support string and securestring values, but you can expand it for other types as well.
To prevent any potential variable name conflicts, the script adds a prefix of “Output_” to the name of the ARM Template output variable name. E.g. “Output_StreamAnalyticsName” from the ARM Template, will become “Output_Output_StreamAnalyticsName”. Of course, you can update this to match your own naming conventions and best practices.
The release pipeline step to call the PowerShell script is configured as per the below screenshot:
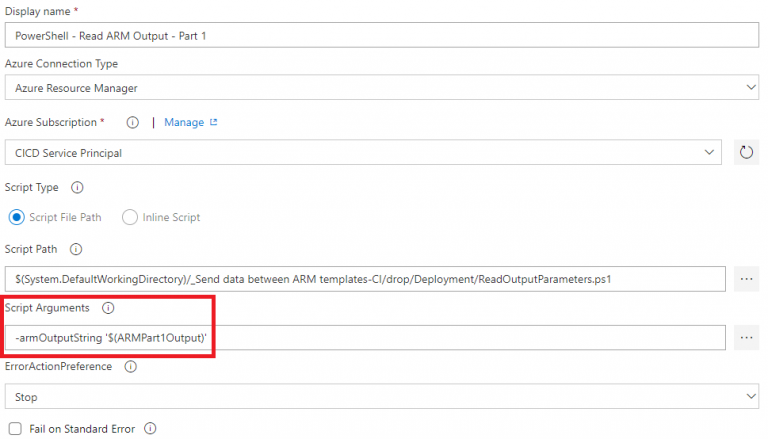
An exact same step is added after the “ARM Template – Deploy Part 2”, but then with the script argument:
-armOutputString '$(ARMPart2Output)'
In the logs of the release pipeline, you can see that the PowerShell script is creating the pipeline variables from the ARM Template Output:
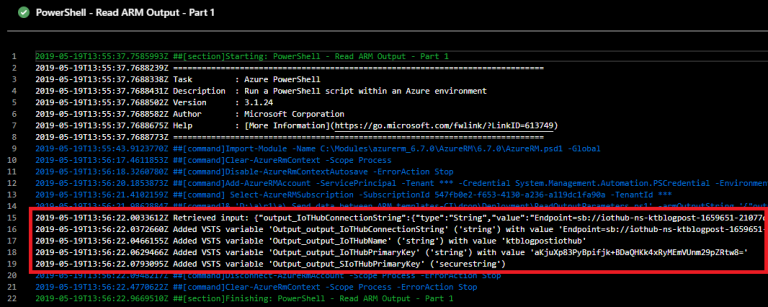
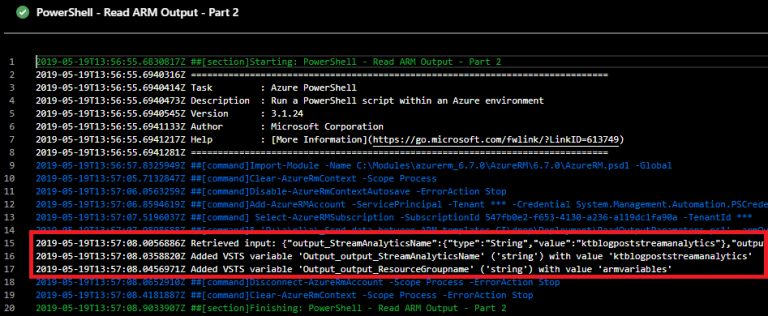
Part 6: Use the pipeline variables in pipeline tasks
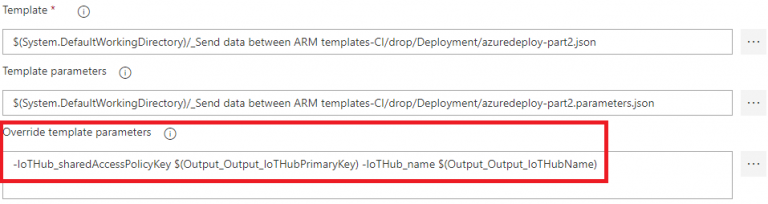
The last remaining step is to use these new pipeline variables when we need them. As with any other pipeline variables, you can use them by using the format “$(variable_name)“, for example: “$(Output_Output_IoTHubPrimaryKey)“. In the current pipeline, for the “ARM Template – Deploy Part 2” step, the template parameters need to be overridden for the IoTHubName and IoTHubPrimaryKey:
In the “PowerShell – Start Stream Analytics” step, the PowerShell script requires the “resourceGroupName” and “streamingJobName” parameters:
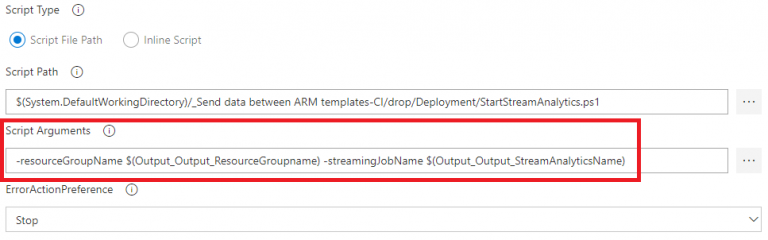
Those two values are outputted by the “Part 2” ARM Template and made available to be used in the release pipeline by the “PowerShell – Start Stream Analytics” step.
Part 7: See all available pipeline variables
While it’s not required to get the solution deployed, the “ReadPipelineParameters.ps1” script and final step in the release pipeline uses a very simple PowerShell command to list all variables:
ls env:
In the deployment logs, you can check what values are available for use. In the below screenshots, you can see our newly added variables as well:
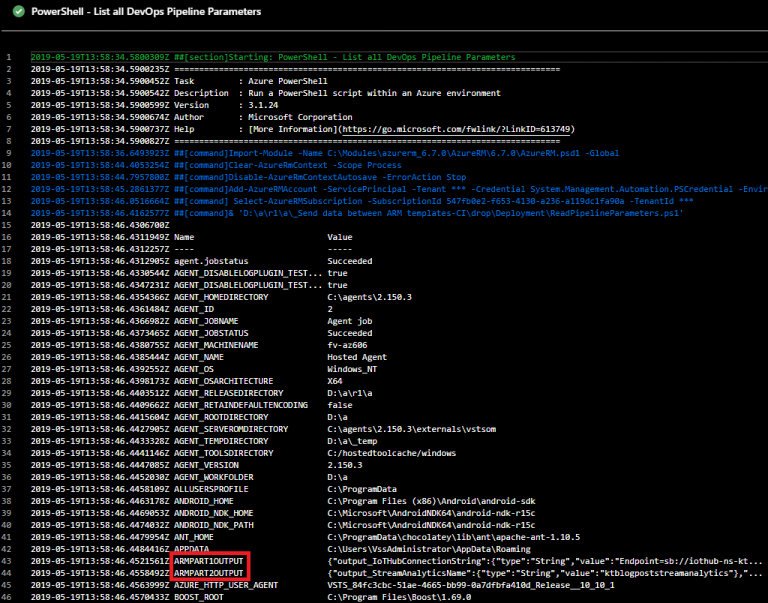

For those comparing the outputs to what we’ve configured so far, you’ll notice that the “Output_SIoTHubPrimaryKey” variable is not listed in the screenshots. This is because it’s a securestring and the value will be kept secret by the CI/CD pipeline. The same applies for the ARM Template output JSON where the value is also automatically omitted:
{“output_IoTHubConnectionString”:{“type”:”String”,”value”:”Endpoint=sb://iothub-ns-ktblogpost-1659651-21077d96a3.servicebus.windows.net/;SharedAccessKeyName=service;SharedAccessKey=aKjuXp83PyBpifjk+
BDaQHKk4xRyMEmVUnm29pZRtw8=;EntityPath=ktblogpostiothub”},”output_IoTHubName”:{“type”:”String”,”value”:”ktblogpostiothub”},”output_IoTHubPrimaryKey”:{“type”:”String”,”value”:”aKjuXp83PyBpifjk+BDaQHKk4xRyMEmVUnm29pZRtw8=”},“output_SIoTHubPrimaryKey”:{“type”:”SecureString”}}
Summary
The Visual Studio solution can be downloaded >HERE<.
I hope this blog post helps you in case you face a (business) requirement to work with ARM Template values through your CI/CD pipeline tasks. By using the PowerShell script and steps from this blog, you should be able to make those values available as pipeline variables to be able to achieve that kind of (business) requirements.